Umi-OCR文字识别工具 v2.1.5.7 绿色免费版 Rapid版
软件大小:141MB
软件语言:简体中文
软件类别:应用工具
更新时间:2026-01-20 05:20:24
版本:v2.1.5.7 绿色免费版 Rapid版
应用平台:Windows平台
- 软件介绍
- 软件截图
- 相关软件
- 相关阅读
- 下载地址
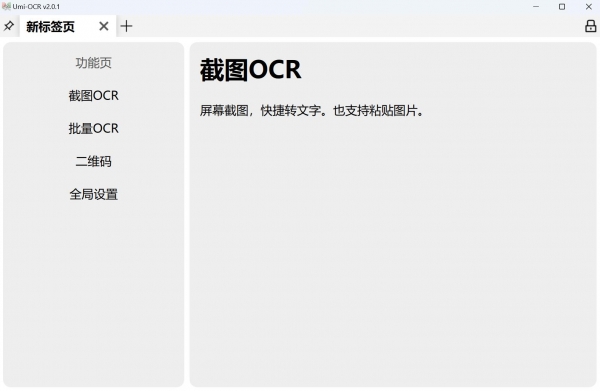
Umi - OCR文字识别工具 v2.1.5.7绿色免费版Rapid版,是一款高效且实用的文字识别神器。它识别精准、速度快,支持多种格式文件识别。我特别喜欢它的截图识别功能,日常工作中,遇到图片里的文字需要编辑却无法复制时,只需用它截图,瞬间就能将文字提取出来,还能直接复制到文档编辑,大大节省了手动录入的时间,提高了工作效率。
本软件有两个版本Umi-OCR_Paddle和Umi-OCR_Rapid:Paddle体积更大,性能更好,但是对电脑配置要求也高;Rapid体积小,相对而言可以用于配置略低的电脑。软件下载后,解压后即可直接使用
Paddle版:Umi-OCR批量图片转文字 v2.1.2 免费绿色版
免费:本项目所有代码开源,完全免费。
方便:解压即用,离线运行,无需网络。
批量:可批量导入处理图片,结果保存到本地 txt / md / jsonl 多种格式文件。也可以即时截屏识别。
高效:采用 PaddleOCR-json C++ 识别引擎。只要电脑性能足够,通常比在线OCR服务更快。
精准:默认使用PPOCR-v3模型库。除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置忽略区域排除水印、设置文块后处理合并排版段落,得到规整的文本。
说明目录
简单上手截图、批量识别~
排版优化如何合并一个自然段内的文字?
忽略区域如何排除截图水印处的文字?
多国语言添加更多PP-OCR支持的语言模型库!
联动翻译软件截图OCR后发送指定按键,触发翻译软件进行翻译
更多小技巧
问题排除无法启动引擎 / 多屏幕截图异常 ?
使用方法:
①前往Gayhub下载公式插件win7_x64_Pix2Text(下载地址:https://simpletex.cn)。
②将上述插件解压后,放到UmiOCR-data\plugins目录(Umi-OCR的解压目录)下。
③打开Umi-OCR,依次点击:全局设置→文字识别→接口改为Pix2Text→点击应用修改。然后就可以正常使用Umi-OCR了。
另外,在设置中建议关闭“启用文字识别”,这样公式识别的准确率更高。
下面我将一张图片中的公式进行识别,准确率还是相当高的,识别后是一串Latex代码,把这串代码复制到下述网址,即可生成公式。
注:Pix2Text插件原作者正在测试中,识别精度还会再提高,可以跟踪一下这个软件。原作者表示Umi-OCR未来将具有独立的公式识别标签页,并提供Latex实时预览等功能。
更新日志
新增:日志机制。在命令行中启动 Umi-OCR 可查看实时日志。高于指定级别(默认为ERROR)的日志被保存到 Umi-OCR/UmiOCR-data/logs 目录中,保存级别可以在全局设置标签页中更改。
新增:大部分标签页能手动切换左右/上下双栏模式。 (#789)
新增:Esc键隐藏主窗口。 (#652)
新增:调整二维码生成相关参数后,自动刷新二维码生成。 (#690)
新增:命令行指令 --reload ,用于重新加载配置文件。
修复:文档识别提取PDF自带的文本内容时,未考虑页面旋转的影响。 (#785)
修复:文档识别生成单层PDF时,未写入原PDF自带的文本内容。
修复:OCR结果展示列表的一些显示Bug和鼠标划选Bug。
修复:调整标签页顺序或删除标签页后,未及时保存顺序信息。
修复:HTTP接口 /api/doc/download 参数 ignore_blank 的错误。
修复:Linux版本截图时,系统任务栏推移顶层窗口,导致截图位置偏移。 (#778)
修复:Linux版本截图后,主窗口的位置与操作前不一致。
优化:图片/文档的异步加载机制。现在可以流畅地加载含有数万个子文件的文件夹,且能预览加载进度。 (#710)
Windows 版本更新第三方依赖库:PyMuPDF 1.24.11 ,fontTools 4.56.0 ,Pillow 10.4.0 ,psutil 10.4.0 ,pynput 1.8.0 ,zxing-cpp 2.3.0
新增UI语言:俄语 Português ,译者:Вячеслав Анатольевич Малышев、Muhammadyusuf Kurbonov。泰米尔语 தமிழ் ,译者:தமிழ்நேரம்。